
Vector Databases: The Foundation of Modern Data Retrieval
Curious about how modern AI applications like recommendation systems and semantic search work? Discover the power of vector databases—designed to handle high-dimensional data efficiently. Learn how they compare, store, and query data, and explore examples like Milvus, Pinecone, and Weaviate. Dive in to unlock the future of data retrieval!
ARTIFICIAL INTELLIGENCE
Dr Mahesha BR Pandit
9/15/20243 min read
Vector Databases: The Foundation of Modern Data Retrieval
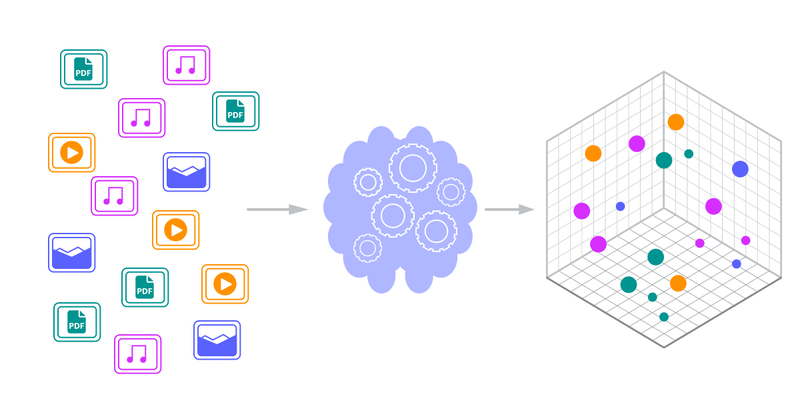
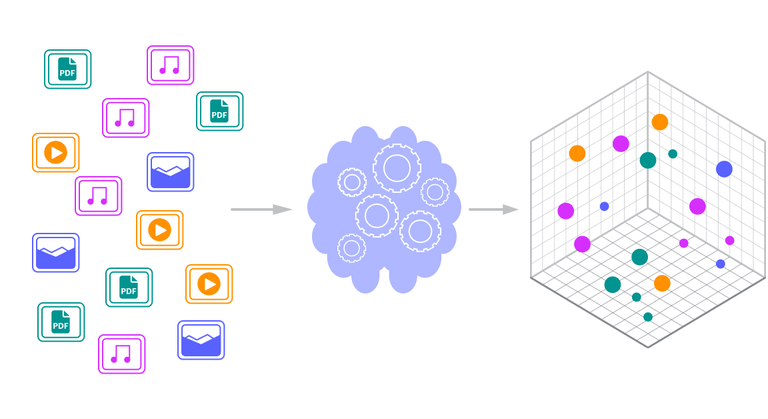
The surge of AI and machine learning applications has brought with it new challenges in managing and retrieving data efficiently. Traditional databases, built for structured or relational data, often fall short when it comes to handling unstructured data like images, videos, and natural language embeddings. This is where vector databases come into play. They are designed to store, index, and query high-dimensional vectors, unlocking the potential of AI-driven search and similarity-based retrieval.
What Are Vector Databases?
At their core, vector databases store numerical representations of data, known as embeddings. These embeddings are often the output of machine learning models that convert complex data—text, images, audio—into mathematical vectors. Each vector captures the data’s meaning or features in a way that can be compared mathematically. This enables tasks like finding similar images, identifying related text, or clustering data points.
Unlike traditional databases, vector databases are optimized for operations like nearest neighbor search, which is essential for comparing vectors and retrieving the most relevant matches. They are the backbone of applications like recommendation systems, semantic search engines, and AI-driven content discovery.
How Do Vector Databases Work?
When you query a vector database, you are not asking for exact matches but for similar ones. This involves techniques like approximate nearest neighbor (ANN) search, which efficiently finds data points closest to the query vector in high-dimensional space. These databases use specialized indexing methods, such as HNSW (Hierarchical Navigable Small World) or KD-trees, to handle the complexity of high-dimensional operations.
The performance of a vector database depends on factors like the size of the dataset, the dimensionality of the vectors, and the type of queries being executed. Modern vector databases are also designed to scale, ensuring they can handle millions or even billions of vectors seamlessly.
Popular Vector Databases and Their Makers
Milvus by Zilliz (https://milvus.io/): A highly scalable and open-source vector database, Milvus is designed for AI-powered applications, offering strong performance for similarity search and recommendation systems.
Weaviate by [Weaviate.io (https://weaviate.io/): A cloud-native vector database that integrates seamlessly with large language models, making it a great choice for semantic search and natural language processing tasks.
Pinecone by Pinecone (https://www.pinecone.io/): Known for its fully managed service, Pinecone specializes in vector search and is popular for integrating with machine learning pipelines.
FAISS by Facebook AI (https://github.com/facebookresearch/faiss): Although technically a library rather than a full-fledged database, FAISS is widely used for similarity search due to its efficiency and flexibility.
Annoy by Spotify (https://github.com/spotify/annoy): Another library rather than a database, Annoy is optimized for memory-efficient nearest neighbor search, making it ideal for recommendation systems.
Qdrant by Qdrant (https://qdrant.tech/): This open-source vector database focuses on high-performance and scalability, with a particular emphasis on handling billions of vectors.
Vespa by Yahoo (https://vespa.ai/): Vespa is a versatile platform that combines vector search with text search, allowing for complex queries across mixed data types.
Redis Vector Search by Redis (https://redis.io/): Known for its speed, Redis offers vector search as part of its module ecosystem, making it suitable for real-time applications.
Elasticsearch with k-NN by Elastic (https://www.elastic.co/): Elasticsearch adds vector search capabilities through the k-NN plugin, enabling integration with its powerful search and analytics platform.
Chroma by Chroma (https://www.trychroma.com/): A lightweight and developer-friendly vector database, Chroma is designed for fast experimentation and small-scale deployments.
PGVector by PostgreSQL (https://github.com/pgvector/pgvector): An extension for PostgreSQL that adds vector search capabilities, PGVector allows combining relational and vector data in one system.
HNSWlib by HNSWlib (https://github.com/nmslib/hnswlib): A library built specifically for HNSW indexing, it is used by many vector databases to power their similarity search features.
Real-World Applications of Vector Databases
Vector databases are transforming the way we interact with data. For instance, in e-commerce, they power recommendation engines by matching user preferences with product embeddings. In healthcare, they help retrieve similar patient records based on symptoms or imaging data. Social media platforms use them to suggest content and connections, while legal and academic systems employ them for document similarity and search.
These databases also shine in multimodal applications, where text, images, and videos are combined. For example, a user can upload an image to a search engine and receive text-based recommendations or vice versa.
Conclusion: The Growing Role of Vector Databases
Vector databases are not just a trend—they are a necessity in the age of AI. By handling the complexity of high-dimensional data and enabling similarity-based search, they open doors to more intelligent, context-aware applications. Whether you are building a cutting-edge recommendation system or a semantic search engine, understanding vector databases can be the first step toward unlocking the full potential of your data.
Image Courtesy: Redis, https://redis.io/blog/vector-databases-101/