
Understanding Graph Databases: A Revolutionary Approach to Data Relationships
Discover the power of graph databases, a revolutionary way to manage interconnected data. Learn how they simplify complex relationships, enhance performance, and enable insights in applications like social networks, e-commerce, and healthcare. Explore their features, use cases, and challenges in this detailed blog. Click to uncover the potential of graph databases!
PROGRAMMINGDATABASES
Dr Mahesha BR Pandit
6/9/20244 min read
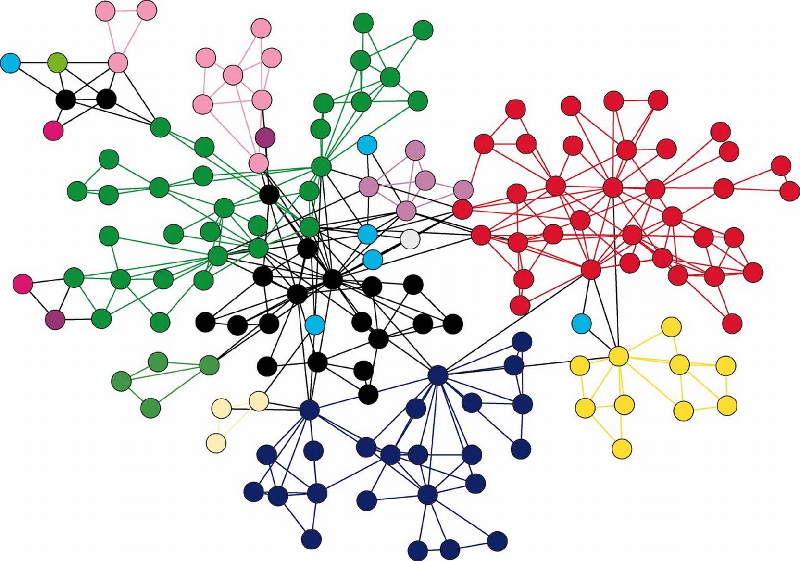
Understanding Graph Databases: A Revolutionary Approach to Data Relationships
In the digital age, where the complexity of data continues to grow, traditional databases often fall short when dealing with interconnected information. Graph databases have emerged as a groundbreaking solution, offering a way to manage and query relationships between data points with unmatched efficiency. By organizing data as nodes and edges, graph databases are uniquely equipped to handle intricate connections and dependencies, making them invaluable in applications ranging from social networks to supply chain optimization.
What is a Graph Database?
A graph database is a type of database designed to represent and store data in a graph structure. In this context, nodes represent entities, such as people, products, or locations, while edges capture the relationships between these entities, such as friendships, transactions, or routes. Unlike traditional relational databases that rely on tables and joins to represent relationships, graph databases make connections a first-class citizen. This architecture allows queries about relationships to be executed quickly and intuitively, even in datasets with millions of nodes and edges.
Graph databases are powered by graph theory, a branch of mathematics that studies how objects are connected. This foundation enables these databases to excel in scenarios where understanding and analyzing relationships are central to the task at hand. With graph databases, finding the shortest path between two points, discovering patterns, or traversing networks becomes both faster and simpler.
A Dozen Graph Databases
Here are twelve noteworthy graph databases, each with unique capabilities and backed by prominent organizations driving innovation in the field.
Neo4j: A powerful, scalable graph database for complex connected data queries. Neo4j, Inc.
Amazon Neptune: A fully managed graph database supporting multiple graph models like Property Graph and RDF. Amazon Web Services (AWS)
Microsoft Azure Cosmos DB: A multi-model database supporting graph data through Gremlin API. Microsoft
ArangoDB: A native multi-model database combining graph, document, and key-value data. ArangoDB GmbH
TigerGraph: A high-performance graph database optimized for real-time analytics on large datasets. TigerGraph, Inc.
JanusGraph: A distributed graph database for storing and querying large graphs. Linux Foundation
Dgraph: A native graph database designed for high-performance and distributed systems. Dgraph Labs, Inc.
RedisGraph: A fast, in-memory graph database built on Redis, supporting the Cypher query language. Redis Ltd.
Cassandra with DataStax Graph: Graph capabilities added to Cassandra for scaling graph workloads. DataStax, Inc.
OrientDB: A multi-model database supporting graph, document, object, and key-value data models. OrientDB Ltd.
AllegroGraph: A graph database specializing in semantic and linked data applications. Franz Inc.
Blazegraph: A graph database designed for RDF/SPARQL-based linked data and semantic web applications. Blazegraph LLC
Key Features of Graph Databases
The defining feature of graph databases is their ability to efficiently handle complex relationships. Traditional databases often struggle with many-to-many relationships, requiring cumbersome joins and nested queries. In contrast, graph databases store relationships alongside data, enabling direct traversal of connections. This approach results in significant performance gains, particularly in scenarios where relationships are dynamic or the dataset is highly interconnected.
Another notable aspect of graph databases is their flexibility. Schema-less designs allow for rapid changes to data structures without the need for extensive migrations. This adaptability makes graph databases well-suited to environments where data evolves frequently, such as social media platforms or recommendation systems.
Graph databases also come equipped with query languages tailored to their structure. For example, Cypher, the query language for Neo4j, is specifically designed to express patterns and relationships in a way that is both powerful and easy to understand. These specialized languages allow developers and analysts to focus on the insights they seek rather than the mechanics of the query.
Applications of Graph Databases
Graph databases have found applications across a wide range of industries, thanks to their ability to model and query relationships naturally. In social networks, they are used to understand connections between users, recommend friends, and analyze influence patterns. The ability to represent relationships directly makes them indispensable for tasks like identifying communities or detecting anomalies.
In e-commerce, graph databases power recommendation engines by mapping relationships between users, products, and transactions. By analyzing purchase histories and user behavior, these systems can deliver personalized suggestions that drive engagement and sales. Graph databases also play a crucial role in fraud detection, where uncovering hidden connections between entities can help identify suspicious activities.
The healthcare industry leverages graph databases to model complex relationships between patients, treatments, and medical outcomes. This capability enables researchers to discover patterns, optimize care plans, and improve patient outcomes. Similarly, in supply chain management, graph databases help track and optimize the flow of goods, ensuring efficiency and minimizing disruptions.
Challenges and Considerations
While graph databases offer compelling advantages, they are not without challenges. One of the primary considerations is their steep learning curve. For teams accustomed to relational databases, transitioning to a graph-based approach requires understanding new concepts, tools, and query languages. However, with adequate training and resources, this barrier can be overcome.
Another challenge lies in scalability. While graph databases handle small to medium-sized datasets effectively, scaling to extremely large datasets with billions of nodes and edges may require careful architecture design and tuning. Advances in distributed graph database systems are addressing this limitation, making large-scale implementations increasingly feasible.
Integration with existing systems can also pose challenges. Organizations with established relational database infrastructures may need to invest in hybrid solutions to leverage graph databases effectively. Ensuring compatibility and smooth data migration are critical steps in such integrations.
Why Graph Databases Matter
Graph databases represent a paradigm shift in how data is stored, queried, and analyzed. By prioritizing relationships, they open up new possibilities for understanding complex systems and uncovering insights that traditional databases cannot provide. Their ability to simplify the representation of interconnected data while delivering exceptional performance makes them a valuable tool in today’s data-driven world.
Whether analyzing social networks, enhancing customer experiences, or optimizing logistics, graph databases offer a unique and powerful approach to tackling modern data challenges. For organizations ready to navigate the interconnected world of data, adopting graph databases is not just an option—it is an opportunity to gain a competitive edge.
Image Courtesy: https://arghya.xyz/articles/neo4j-graph-database-1/